



הפעלת NVIDIA Riva על גבי-Red Hat OpenShift עם Dell PowerFlex
מאמר מאת נדב מדר, Storage, Platforms & Solution Sales at Dell Technologies
לפני מספר חודשים, Dell ו-NVIDIA פרסמו validated design להפעלת NVIDIA Riva על גבי-Red Hat OpenShift עם Dell PowerFlex. ארכיטקטורה זו מציגה את העצמה של NVIDIA Riva ו- Dell PowerFlex לטיפול בכל מה שקשור לעיבוד אודיו.
לאלו מכם המכירים את יישומי ASR, TTS ו-NMT, אולי תהיו סקרנים לדעת כיצד ניתן לסנתז את המושגים הללו לכדי משהו פשוט. בואו ללמוד.
NVIDIA Riva
למי שלא מכיר את NVIDIA Riva, בואו נתחיל משם.
NVIDIA Riva היא ערכת פיתוח תוכנת בינה מלאכותית (SDK) לבניית AI pipelines לשיחה, המאפשרת לארגונים לתכנת בינה מלאכותית במערכות הדיבור והשמע שלהם. זה יכול לשמש כעוזר חכם או אפילו עורך ההערות בפגישה הבאה שלכם. סופר מגניב, נכון?
עם זאת, NVIDIA Riva מאפשרת לכם לבנות Pipelines AI (דרך להפוך תהליכי עבודה של למידת מכונה לאוטומטית) לשיחות בזמן אמת, הניתנות להתאמה אישית מלאה, שלמעשה זו דרך מפוארת לומר שהיא מאפשרת לעבד דיבור במגוון דרכים, כולל זיהוי דיבור אוטומטי (ASR - automatic speech recognition), טקסט- לדיבור (TTS) ותרגום מכונה "עצבית" (NMT - neural machine translation):
- זיהוי דיבור אוטומטי (ASR) – למעשה הַכְתָּבָה. אספקת AI עם הקלטה וקבלת תמליל כתוצר- שומר הערות כמעט באופן מושלם לפגישה הבאה שלכם.
- טקסט לדיבור (TTS) - המחשב קורא את מה שאתם מקלידים. בעבר זה התאפשר בקול מונוטוני. זה קיים למעלה מכמה עשורים והתפתח במהירות עם קולות ותגובות זורמות יותר.
- תרגום מכונה "עצבית" (NMT) - תרגום שפה מדוברת לשפה אחרת כמעט בזמן אמת. כלי מעולה לשיפור תקשורת, שיכול לסייע לארגונים בהתרחבות עסקית.
כל אפליקציה היא רבת עוצמה בפני עצמה, אז תארו לעצמכם מה ניתן כאשר אנחנו מפגישים את ASR, TTS ו-NMT ביחד, במיוחד עם מערכת מגובה בבינה מלאכותית. תארו לעצמכם שיש לכם מערכת תמיכה טכנית שיכולה לבחון שיחות תמיכה, נשמעת כאילו אתם מדברים עם מהנדס תמיכה בפועל, ויכולה לספק תמיכה במספר שפות. במילה אחת: פורץ דרך.
NVIDIA Riva מאפשרת לארגונים להתייעל בטיפול בתקשורת מבוססת דיבור. כאשר ארגונים מתייעלים בתחום אחד, הם יכולים להשתפר בתחומים אחרים. זו הסיבה ש-NVIDIA Riva היא חלק מפלטפורמת התוכנה NVIDIA AI Enterprise, המתמקדת בייעול פיתוח והטמעת AI לייצור.
אולי אני גורם להכל להישמע פשוט, אולם אלה שיוצרים מודלי שפה גדולים (LLMs) סביב תוכנות דיבור ותרגום רב-לשוני יודעים שזה לא כך. זו הסיבה ש-NVIDIA פיתחה את Riva SDK.
מערכת ההפעלה המשחקת תפקיד עצום במה שניתן לעשות עם יישומים אלה. Red Hat OpenShift מאפשרת זיהוי דיבור בעזרת AI , כל זאת הודות לארכיטקטורה העוצמתית המבוססת קונטיינרים, ארכיטקטורת Micro Services ותכונות האבטחה החזקות שלה. זה מאפשר התאמת הפתרון לצרכי העבודה הנוכחיים של הארגון ובמידת הצורך, ניתן לגדול בצורה פשוטה ושקופה.
למה האחסון חשוב?
אתם בודאי תוהים איך האחסון משתלב בכל זה. זו שאלה מצוינת. עבור NVIDIA Riva תזדקקו לאחסון בביצועים גבוהים. אחרי הכל, היא נועדה לעבד ו/או ליצור קבצי שמע והיכולת לעשות זאת כמעט בזמן אמת דורשת מערכת אחסון אמינה, העלת יכולת גידול בהתאם לצרכים, וכמובן בעלת ביצועים גבוהים כמו Dell PowerFlex.
בנוסף, יישומי AI הופכים ליישומי מיינסטרים בארגון ואמורים להיות מסוגלים לפעול לצד עומסי עבודה קריטיים אחרים תוך שימוש באותו אחסון.
בשלב זה אתם בטח סקרנים לדעת מה התוצאות שמספקת NVIDIA Riva על Dell PowerFlex.
ביצועי ASR ו-TTS
צוות ההנדסה של PowerFlex ערך בדיקות מקיפות באמצעות מערך הנתונים מוכן ( LibriSpeech dev-clean) הזמין ב- Open SLR. באמצעותו ביצעו בדיקת זיהוי דיבור אוטומטי (ASR) עם NVIDIA Riva. עבור כל בדיקה, הזרמת המידע (Streams) הוגדלה מ-1 ל-64, 128, 256, 384 ולבסוף 512, כפי שמוצג בגרף הבא.
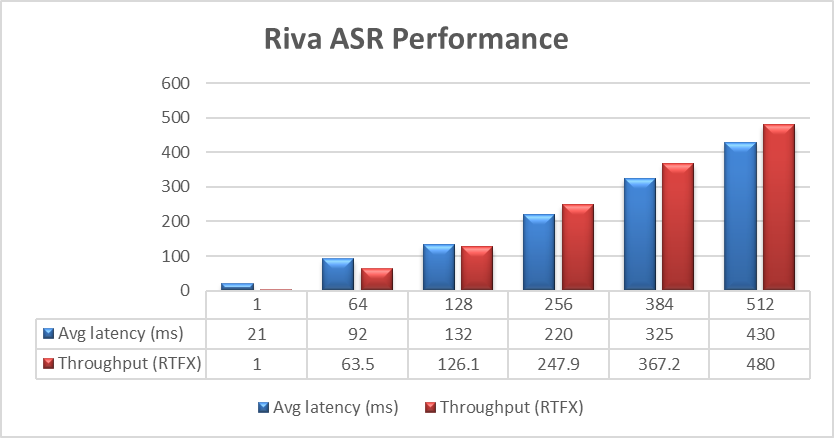
מטרת הבדיקות לקבל את התוצאה עם ה-Latency הנמוך ביותר עם Throughput הגבוה ביותר. ה- Throughput נמדד ב-RTFX, או משך האודיו שתומלל חלקי זמן החישוב. במהלך הבדיקות, ניצול ה-GPU היה כ-48% ללא צווארי בקבוק של PowerFlex. תוצאות דומות לממצאי NVIDIA עצמה במדריך למשתמש NVIDIA Riva.
צוות ההנדסה של PowerFlex עשה בנוסף גם בחינת מהירות תמלול הטקסט באמצעות NVIDIA Riva וגם חקר את מהירות המרת הטקסט לדיבור (TTS). החל בהזרמת מידע יחידה, עבור כל הפעלה, כמות Streams משתנה ל-4, 6, 8 ו-10, כפי שמוצג בגרף הבא.
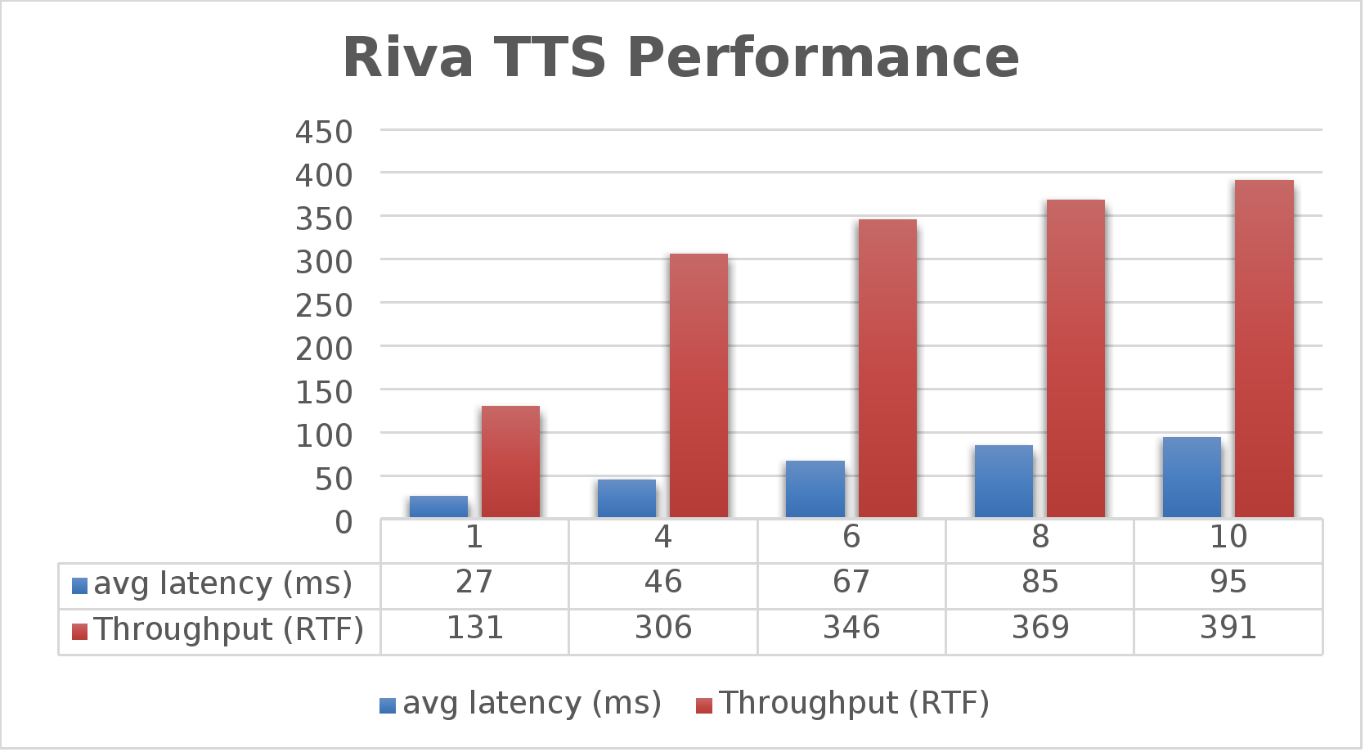
שוב, המטרה לקבל LATENCY ממוצע נמוך עם Throughput גבוהה. ה- Throughput (RTFX) במקרה זה היא משך האודיו שנוצר חלקי זמן החישוב. כפי שניתן לראות, תפוקת RTFX של 391 עם LATENCY של 95ms עם עשרה Streams. ראוי לציין שבמהלך הבדיקה, ניצול ה-GPU היה כ-82% ללא צווארי בקבוק באחסון.
צוות ההנדסה של Dell PowerFlex Solutions יצרו validated architecture המפרטת כיצד כל התוצאות הושגו וכיצד ארגון יכול לשכפל אותן במידת הצורך.
כעת, כדי לשים את כל זה בפרספקטיבה, עם PowerFlex אתם יכולים להשיג תוצאות נהדרות הן בשפה המדוברת הנכנסת לארגון והן בהמרת טקסט לדיבור. חברו את היכולת הזו לכמה כלי genAI אחרים, כמו NVIDIA NeMo, ותוכלו ליצור מערכות מתוחכמות עבור הארגון שלכם.
לדוגמה, אם מודל ASR משויך למודל שפה גדול (LLM) עבור ה-HELP DESK, משתמשים יכולים לשאול שאלות מילוליות, ולאחר שימצאו התשובות - הוא יוכל להשתמש ב-TTS לספק את התשובות. תחשבו מה משמעות הדבר לארגונים.
מידע נוסף ניתן למצוא במסמך, או באמצעות פניה למומחים שלנו.